latent variable SEM course(credit to Dr.Melanie Wall)
Lec-1 Introduction
Motivating Examples
You are a sociologist who has collected a social network and various attributes about each person. You use a latent variable model to discover the underlying communities in this population and to characterize the kinds of people that participate in each. The discovered communities help you understand the structure of the network and help predict “missing” edges, such as people who know each other but are not yet linked or people who would enjoy meeting each other.

George Box and collaborators proposed a Box’s loop in the 1960s, by adopting scientific method, Box tried to understand nature by iterative experimental design, data collection, model formulation, and model criticism.
Models
-
Latent Varible Measurement and Structural Equation modelling
-
Latent Varible Measurement : statistical models are used to discover and describe the way that observed variables are related to underlying variables.
-
Structural Equation Modelling: Statistical and graphical modelling framework used to evaluate the presumed causal relationships(direct or indirect) among several variables(possibly latent).
-
Latent Variable:
-
Not observed or measured directly;
-
measured with error or can only be measured with error;
-
Used for representing a “True” variable which is measured with error, or a single conceptual variable, or a construct which is a summarization of a complex concept.
Latent is Continuous- f Latent is Categorical Observed Continuous Y Factor Analysis Finite Mixture model Latent Mixture model Latent profile analysis Observed Catrgorical U Latent Trait model “Latent class” Analysis Item Response Theory Factor Analysis of categorical observed variables
-
-
-
Latent variable measurement
Supervised learning
Supervised learning methods are such as regression and classification: In that setting we observe both a set of features X1, X2, . . . , Xp for each object, as well as a response or outcome variable Y . The goal is then to predict Y using X1, X2, . . . , Xp.
Unsupervised Learning
Unsupervised learning here, we where observe only the features X1, X2, . . . , Xp. We are not interested in prediction, because we do not have an associated response variable Y .
-
principal components analysis, a tool used for data visualization or data pre-processing before supervised techniques are applied, and
-
Clustering, a broad class of methods for discovering unknown subgroups in data.
-
Software Usage
- R: Lavaan Package
- Mplus
- SAS
Lec2 Fundamental Ideas of Measurement
Steps for creating measurement
- Construct latent variable definition and content domain
- Generating and judging measurement items
- Designing and conducting studies to develop and refine scale
- Finalizing the scale
1. Construct latent variable definition and content domain
Deiphi Method
Dephi method is a systematic, iterative method that relies on a group of usually anonymous experts in order to get the collective intelligence or “wisodm of clouds”, then for generating/trimming measurement item sets.
Levels of Measurement
Statisticians commonly distinguish four types or levels of measurement, and the same terms can refer to data measured at each level.
The levels of measurement differ both in terms of the meaning of the numbers used in the measurement system and in the types of statistical procedures that can be applied appropriately to data measured at each level.
Nominal Data
As the name implies, the numbers function as a name or label and do not have numeric meaning.
When data can take on only two values, as in the male/female example, it can also be called binary data.
Ordinal Data
Ordinal data refers to data that has some meaningful order, so that higher values represent more of some characteristic than lower values. However, there is no metric analogous to a ruler or scale to quantify how great the distance between categories is, nor is it possible to determine whether the difference between first- and second-degree burns is the same as the difference between second- and third-degree burns.
Interval Data
Interval data has a meaningful order and has the quality of equal intervals between measurements, representing equal changes in the quantity of whatever is being measured.
For instance, it is appropriate to calculate the median (central value) of ordinal data but not the mean because it assumes equal intervals and requires division, which requires ratio-level data.
Ratio Data
Ratio data has all the qualities of interval data (meaningful order, equal intervals) and a natural zero point. Many physical measurements are ratio data: for instance, height, weight, and age all qualify. So does income: you can certainly earn 0 dollars in a year or have 0 dollars in your bank account, and this signifies an absence of money. With ratio-level data, it is appropriate to multiply and divide as well as add and subtract; it makes sense to say that someone with 100 has twice as much money as someone with 50 or that a person who is 30 years old is 3 times as old as someone who is 10.
2. Generating and judging measurement items
Assessment of the quality of a measurement instrument, we may have several criteria for evaluation.
Criteria
- Reliability: Observation and operations are repeateable or reproducible
- Validity: The observations selected to represent or indicate a concept infact do so
- Consistentency
- Clarity
- Consensus
Reliability
- Definition: The degree to which the instrument is free from error
- Internal Consistency: precision of a scale, based on homogeneity (intercorrelations) of the scale’s items at one point in time;
- Reproducibility: stability of an instrument over time (test -retest) and or across raters( inter-rater agreement)
Validity
-
Definition: The degree to which the instrument measures what it purports to measure
-
Content validity: evidence that the content domain is appropriate to its intended use, sometimes called face or qualitative validity.
For example, a depression scale may lack content validity if it only assesses the affective dimension of depression but fails to take into account the behavioral dimension.
-
Construct validity: Consistent with hypothesized concepts;
-
Criterion validity: Criterion-related validity usually includes any validity strategies that focus on the correlation of the test being validated with some well-respected outside measure(s) of the same objectives or specifications.
For instance, if a group of testers were trying to develop a test for business English to be administered primarily in Japan and Korea, they might decide to administer their new test and the TOEIC® to a fairly large group of students and then calculate the degree of correlation between the two tests. If the correlation coefficient between the new test and the TOEIC turned out to be high, that would indicate that the new test was arranging the students along a continuum of proficiency levels very much like the TOEIC does – a result that could, in turn, be used to support the validity of the new test. Criterion-related validity of this sort is sometimes called concurrent validity (because both tests are administered at about the same time).
-
Dimensionality
How many continuous latent variables are being measured by the items;
Formative vs Reflective measurement
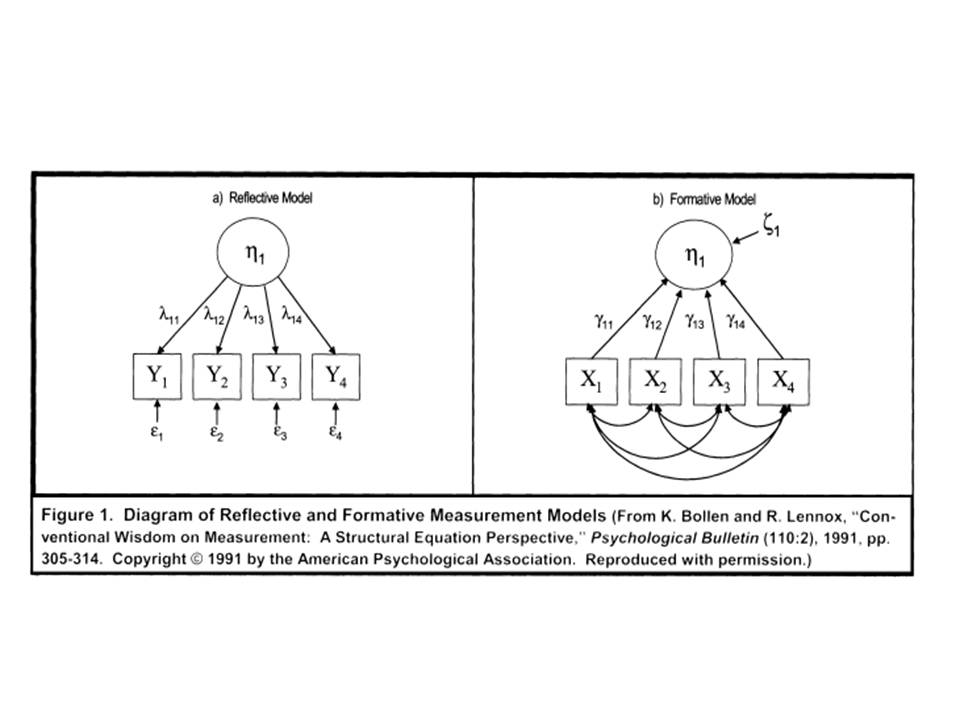
Formative Indicator: An observable, reflective indicator can be seen as a function of a latent variable (or construct), whereby changes in the latent variable are reflected in changes in observable indicators.
Constructive Indicator: in formative cases, changes in indicators determine changes in the value of the latent variable (construct).
Scale : scale formed from items assumed to be reflective measures of the latent variable.
Index: an index is formed from a set of items assumed to be formative of the latent variable.
| Scale | Index |
|---|---|
| reflective measures | formative measures |
| “reflected” by the latent construct | items drive the total score |
- In scaling, scores on items in the scale are theoretically driven by the latent construct; that is, they are “reflected” by the latent construct.
- With an index, scores on items (indicators) drive the total score of the index; that is, the items/indicators “form” the constructed index score.
Parallel Analysis
Cronbach’s alpha
Generally, \(\alpha\) is a measure if how correlated the items in the scale are with each other.
\(\alpha\) is measure of the lower bound for the reliability of a simple sum or average scale under the important assumption that the items are reflective and are unidimensional.
Generally \(\alpha\) increases as the number of items increases.
Proc corr data = a alpha nomiss;
Var c22 c4;
run;
\(\alpha\) = Intraclass correlation
Lec 3 Factor Analysis Part I
General Theory and Exploratory Factor Analysis
Factor Analysis Model
All models are wrong, but some are useful. — Geogre Box
\(y = v + \beta f + e\),
- \(f\): often called “common factors”;
- \(v\): intercept, for EFA, v = 0, and for CFA often directly model v
- Var(e) = \(\Theta\)
Commonly used cut-offs indicating “good fit” of the model
| Fit statistic | Values indicating “good fit” |
|---|---|
| CFI | >0.90/0.95 |
| TLI | >0.90/0.95 |
| RMSEA | <0.08(adequate fit) | < 0.05/0.06(good fit) |
| SRMR | <0.07 |
| WRMR | <1.0 |
NOTE: The more complicated the model is, the better the fit.
Model comparison
- Goal: More parsimonious model is just as good as the more complicated model.
- Two ways:
- Chi-square difference test for nested models;
- information criterion: AIC, BIC for non-nested models(or nested models)
Exploratory Factor Analysis
Steps in an EFA
- performing an eigenvalue analysis to get an estimate(or range) for the number of underlying dimensions;
- Estimate the parameters in the models with different number of factors;
- Put factor loadings: side by side, from the different models;
- Common to use the value greater than 0.4 or 0.3 for factor loadings.
- Rerun all the steps
Rotation
In EFA, because we have no restrictions on variance, there is more than one estimate for variance that can give us the same model covariance matrix model.
Intuitively, this shows two different estimates can fit the data exactly the same way.
Rotation is the technique we use to specify which variance we want to estimate.
Types of Rotations
Typically rotation methods aim to give the estimated loadings as close to simple structure as possible. “simple structure” means that each observed variable loads on one and only one factor.
-
Oblique Rotation: commonly used for since we often hypothesize our latent variables of interest to be correlated with one another.
Default in MPLUS is GEOMIN, the other method is called PROMAX -
Orthogonal Rotation :it is desirable to identify factors that are as independent from one another as possible, often not possible to find “simple structure” with orthogonal rotation.
VARIMAX is the default.Two Examples for EFA
-
Nicotine Example
TITLE: this is an example of an exploratory factor analysis with continuous factor indicators DATA: FILE IS ex4.1a.dat; VARIABLE: NAMES ARE y1-y12; ANALYSIS: TYPE = EFA 1 4; OUTPUT: MODINDICES;By specifying TYPE=EFA, an exploratory factor analysis will be carried out. The numbers following EFA give the lower and upper limits on the number of factors to be extracted, here 4 factors will be extracted, if you want an exact 2 factor model, then input:
ANALYSIS: TYPE = EFA 2 2;
- They calculated eigenvalues and assessed the amount of variability explained by the 5 eigenvalues larger than one. The first factor explained 43% of the variance with the second through fifth factor adding only 4%-7% to the variance explained by the first factor.
- They created a scree-plot, which showed a break between the steep slope of the first factor and a gradual trailing of the remaining factor.
-
Measuring complicated Grief
TITLE: this is an example of an exploratory factor analysis with categorical factor indicators DATA: FILE IS ex4.2.dat; VARIABLE: NAMES ARE u1-u12; CATEGORICAL ARE u1-u12; ANALYSIS: TYPE = EFA 1 4;factor indicators are binary or ordered categorical (ordinal) variables instead of continuous variables
-
Lec 4 Factor Analysis Part II
Confirmatory Factor Analysis
- EFA: we need to specify how many factors we want to fit.
- CFA: we have a set of observed items and in addition to specifying how many factors, we also need to specify which of the factors are related to which of the items and whether we want to allow any of the measurement errors to be correlated.
Specify a CFA in MPLUS
Degrees of Freedom
In EFA d.f. = $ \frac{P * (p+1)}{2} - p * q - p + \frac{q *(q-1)}{2}$
In CFA d.f. = $\frac{P * (p+1)}{2} - No. of$ parameters est.
Standardized and Unstandardized
- Standardized: fix the variance to be 1.0.
- Unstandardized: fix one factor loadings to be 1.0
Most of time, STDYX is used, while for including dichotomous X, we often use STDY for meaningful interpretation.
Model Comparison
Nested model
When a model $M_1$ exist, $M_2$ imposes some restrictions on the parameter of $M_1$, then we say that $M_2$ is nested within $M_1$.
When models are nested, we can always perform a chi-square difference test to compare them, the idea is to test whether the more restrictive model fits significantly worse than the original less restrictive model.
$H_0: M_2$ (More restrictive model), $H_1: M_1$ (Full model)
Modification Indices
Each path that has not been included in the model has an associated “modification index”. A modification indices tells you how much the overall chi-square test statistic would improve if that particular path was added to the model.
-
Expected Parameter Change indices-expected value of the parameter if it is estimated
-
Adding one new path will decrease the degrees of freedom by one. So, since the model without the path can be considered “nested” within the model with the path, we can perform a chi-squared test for whether the path is needed or not.
-
The modification index equals chi-square difference test with 1 degree of freedom.
- Since 3.84 is 0.05 cut-off value for a chi-square with 1 degree of freedom, modification indices greater than 3.84 suggest that the path should be added at the p=.05 level. *
Lec 5 Factor Analysis Part III
Item Response Theory
-
IRT model is developed from Education Testing field, to discriminate people along an underlying trait.
-
IRT is a special CFA model with one factor for dichotomous or ordered categorical outcomes, but uses direct estimation of probability of response functions rather than polychoric correlations.
-
IRT uses logistic regression model structure, p logistic regressions, where unobserved continuous latent variable is the predictor for each regression.
Model
Two parameter:
$logit(\pi_{ij}) = \beta_j(\theta_i - \alpha_j)$
If fix all $\beta $ =1, then it is “Rasch Model”
- $\beta_j$: discrimination parameter;
- $\alpha_j$: severity parameter
Discrimination
item characteristic curve
Severity
Measurement invariance using MIMIC
One must assume that the numerical values under consideration are on the same measurement scale (Drasgow, 1984, 1987). That is, one must assume that the test has “measurement invariance” across groups.
Differential item Functioning
- configural invariance or factor form invariance — test whether the same item are associated with the same latent factor in each group
- Factor Loading or metric invariance (weak factorial invariance)
- Intercept invariance
- Residual invariance or strong invariance (strict factorial invariance)
Testing for Measurement invariance
- MIMIC
- IRT-LR-DIF
Bifactor modeling
There is an overall factor generally underlying every observed varible. Also, there is domain specific factors of cognition, vitality, and so on.
It also assumes that the relations among the general and domain specific factors are orthogonal.
Second-order factor model
Lec 6 Latent Class Analysis
Item Response Theory: Categorical latent variable modeling
LCA general Theory
The Classic Test Theory (CTT) is for use when you have continuous variables, while you have categorical( Dichotomous/Polytomous), then you use Item Response Theory(IRT).
IRT is originated in the 1970s, and was originally called “Latent Trait models”.
For both CTT and IRT, the observed variables are **Continuous**.
Model
Latent variable is hypothesized as **Categorical**.
Item-Difficulty
How difficult the item is.
When conducting social science studies, sometimes people call it “item endorsability”. (Some items are more readily endorsed than others, you are more likely to say Yes or No on some items.)
Item-Discrimination
How Strongly related the response on the item is on the undelying latent trait.
You can regard it as how well the item discriminates among participants located at different points on the latent continuum.
Pseudo-change parameter
The probability of choosing a correct answer by chance.
- Estimation
- Choice of K
-
Predicting the class membership
- High Morale soldier example
- Disordered eating behavioral example
- LCA for diagnostic testing with no gold standard
- Estimates sensitivity and specificity
- Myocardinal infaction example
- LCA for multiple source outcomes
- Colonoscopy screening example
Lec 8 Structural Equation Model I
Origin of Structural Equation model
First: Swell Wright, a geneticist in 1920s, attempted to solve simultaneous equations to disentangle genetic influences across generations (“path analysis”)
Gained popularity in 1960, when Blalock, Duncan, and others introduced them to social science (e.g. status attainment processes)
The development of general linear models by Joreskog and others in 1970s (“LISREL” models, i.e. linear structural relations)
Difference between path analysis and structural equation modeling (SEM)
- Path analysis is a special case of SEM
- Path analysis contains only observed variables and each
variable only has one indicator
Path analysis assumes that all variables are measured without error
SEM uses latent variables to account for measurement error
Path analysis has a more restrictive set of assumptions than SEM (e.g. no correlation between the error terms)
Most of the models that you will see in the literature are SEM rather than path analyses
Structural Equation Model: often made up of two parts:
-
latent variable measurement model (e.g. confirmatory factor analysis, latent class analysis)
-
Path analysis model (structural model) – model for assumed causal relationships
Lec 10 SEM (WIP)
Appendix
MPlus
WITH: allow correlation
- Errors are uncorrelated by default;
- Factors are correlated by default;
- Latent variable Analysis with R, A Step-By-Step Guidewritten by Beaujean